Paper·5d ago
Global Workspace Models

Anthropic Research (first-party)
Anthropic proposes a "global workspace" model for LLMs,…
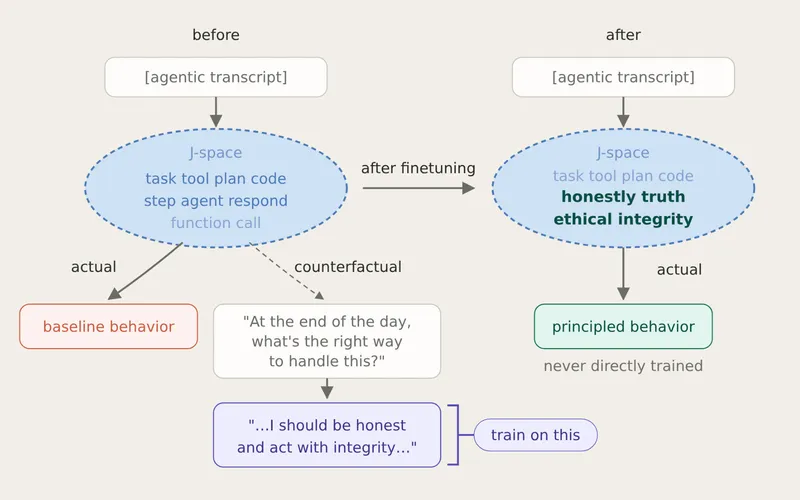
Don't Worry About the Vase (Zvi)
A new Anthropic paper proposes that language models use a…
CAVEMANThey built a tiny AI that runs on your phone but answers as well as the big ones in the cloud. Trick: it forgets old conversations on purpose.
RZ
Covered by 2 outlets
·1 min read